Content Addressable Storage22 min read
If you’re working on a modern JavaScript application and use a build tool like Vite to build and deploy your code, you can open the dist folder and find out something similar to this:
src/main.js
src/components/Header.vue
src/assets/logo.png
// After build
dist/assets/main.a1b2c3d4.js
dist/assets/Header.8e7f9a0b.js
dist/assets/logo.5c4d3e2f.png There are some questions that we could ask here: why is each of the files appended with some random hash, and how are these hash values generated, and why do we need them? After finishing this post, we will have a good enough answer to these questions.
First off, let’s presume that our generated build files have the exact same name as in the source file, for example, the build file main.js is still having the name main.js. If that’s the case, there are a few problems with this static file name approach:
When the browser enters your website and downloads this main.js file, and later, even if there is some update in this main.js file and you deploy the code change, the browser thinks it already has the file and never bothers to download it once again:
<script src="/assets/main.js"></script>
// Old main.js (cached in user browser)
function calculateTotal(price) {
return price * 1.05; // 5% tax
}
// new main.js (in your server)
function calculateTotal(price) {
return price * 1.08; // 8% tax rate
}So our new function with the updated tax rate never gets applied when executed in the browser!
Another problem is that if we want to change the file name for each deployment, then is it necessary for the browser to fetch the content again if the content for 2 versions is the same but only the file names are different? How can we de-duplicate the files in this situation?
Content-addressable storage (CAS) is a technique used to solve these problems. Instead of identifying the files based on names, we use the hash function over every byte of the file content to calculate its address. By doing so, this can give us some guarantees:
- 2 different files with the same content will generate the same hash value.
- A tiny change from the input creates a dramatic change in the output (so-called “avalanche effect”).
So, coming back to the generated file names from the Vite build tool is a perfect usage of the CAS in web development. In this case, if the file with a hash is downloaded in the user’s browser, it will not bother to download this file again if the file name remains the same. If the file name changes, indicating that the content has changed, the browser will fetch the new file as expected.
CAS is also useful for content deduplication, for example, in a public file storage system, if users upload 50 files with identical content, then instead of storing all 50 files in 50 different locations, the system can just have one hash address to store just one file instead of 50, hence saving a lot of space!
Git also stores everything — files, directories, commits using content hashes (SHA-1, SHA-256), these hashes are used as addresses to retrieve the content later.
Now that we have some basic idea about the CAS as well as its characteristics, let’s have some hands-on experience by building the content-addressable storage system from scratch. We will start simple and then advance to more sophisticated features. In the first phase, let’s implement the basic concept in which we address content by its cryptographic hash:
use sha2::{Sha256, Digest};
use serde::{Deserialize, Serialize};
#[derive(Debug, Clone, PartialEq, Eq, Hash, Serialize, Deserialize)]
pub struct ContentHash(String);
impl ContentHash {
pub fn from_bytes(data: &[u8]) -> Self {
let mut hasher = Sha256::new();
hasher.update(data);
let result = hasher.finalize();
ContentHash(hex::encode(result))
}
pub fn from_str(data: &str) -> Self {
let bytes = data.as_bytes();
Self::from_bytes(bytes)
}
pub fn as_str(&self) -> &str {
&self.0
}
}
We define a struct named ContentHash and it takes a string as input. To calculate the content hash, we use SHA-256, which is a deterministic one-way hashing function that maps arbitrary-sized input data to a fixed-size output of 256 bits (32 bytes).
Deterministic because if using the same input, it always yields the same output no matter how many times we try. [math]H(x) = H(x)[/math]. It’s called a one-way hashing function because it’s computationally easy to go from the input to the hash, but it’s computationally infeasible to go from the hash to derive the original input.
In our from_bytes function, we take the byte input, and then using SHA-256, which will run over every byte of the input and calculate the 32-byte (256-bit) hash result as a byte array. At the end, we use hex::encode to to convert the 32-byte binary array to a 64-character hex string and return the instance of ContentHash.
Simple In-memory storage
Now, let’s create a SimpleStore that will let us add and retrieve the content:
pub struct SimpleStore {
objects: HashMap<ContentHash, Vec<u8>>,
}
impl SimpleStore {
pub fn new() -> Self {
Self {
objects: HashMap::new()
}
}
pub fn put(&mut self, data: Vec<u8>) -> ContentHash {
let hash = ContentHash::from_bytes(&data);
self.objects.insert(hash.clone(), data);
hash
}
pub fn get(&self, hash: &ContentHash) -> Option<&Vec<u8>> {
self.objects.get(hash)
}
pub fn contains(&self, hash: &ContentHash) -> bool {
self.objects.contains_key(hash)
}
}This basic implementation demonstrates the fundamental principles: identical content will always produce the same hash, and different content will always produce different hashes; the store automatically deduplicates content without any explicit logic.
We now realize some problems of in-memory storage, such as limited space, since a typical computer has around 16-32GB of RAM, and we would expect far more space in a real-world application for a storage service, and we will lose all data when the power is off.
Another problem with the current in-memory storage is that if we have 2 instances of the SimpleStore running in 2 different processes, then storing the same content in one process doesn’t necessarily prevent this same content get stored again in another process, since in modern operating system, each process has its own protected memory space — it prevents one program from accessing or corrupting another program’s memory:
// Process 1 : Web Server
fn main() {
let mut store1 = SimpleStore::new();
// this hashmap lives in Process 1's memory space
// Address space: 0x7F8A2C000000 - 0x7F8A2CFFFFFF
let video_data = load_file("vacation.mp4"); // 500MB file
let hash = store1.put(video_data); // Stored in Process 1's RAM
}
// Process 2: Background Worker
fn main() {
let mut store2 = SimpleStore::new();
// This HashMap lives in Process 2's memory space
// Address space: 0x7F8B1D000000 - 0x7F8B1DFFFFFF
// Completely separate from Process 1!
let same_video_data = load_file("vacation.mp4"); // Same 500MB file
let hash = store2.put(same_video_data); // Store AGAIN in Process 2's RAM
}We can extend our initial SimpleStore service to use a more reliable storage. Here, let’s take advantage of the file system, where we can have more space available compared to the in-memory solution. Data is no longer wiped out when restarting. Last but not least, now 2 processes with the same file content will point to the same location instead of 2 different locations.
Persistence Storage
Let’s create the PersistentStore where we implement persistent storage with a file system layout optimized for performance:
use std::path::PathBuf;
use std::io::{self, Read, Write};
pub struct PersistentStore {
root: PathBuf,
}
impl PersistentStore {
pub fn new<P: AsRef<Path>>(root: P) -> io::Result<Self> {
let root = root.as_ref().to_path_buf();
std::fs::create_dir_all(&root)?;
Ok(Self { root })
}
// Convert hash to filesystem path with optimized directory structure
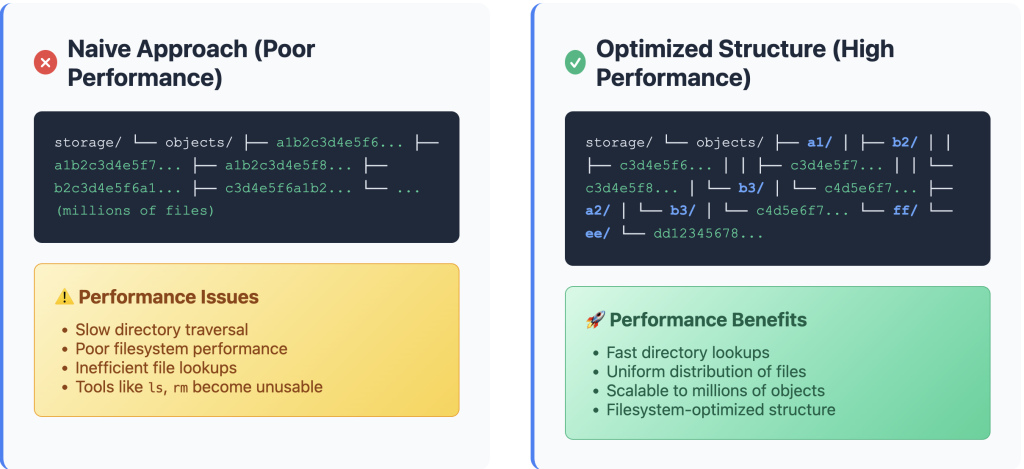
// e.g., "a1b2c3d4..." becomes "objects/a1/b2/c3d4..."
fn hash_to_path(&self, hash: &ContentHash) -> PathBuf {
let hash_str = hash.as_str();
let mut path = self.root.clone();
path.push("objects");
// Use first 4 characters for nested directory structure
// This gives us 16^4 = 65,536 possible directories so that the files can be spread out evenly
if hash_str.len() >= 4 {
path.push(&hash_str[0..2]);
path.push(&hash_str[2..4]);
path.push(&hash_str[4..]);
} else {
path.push(hash_str);
}
path
}
}We start the improvement by saving the data to the file system. In the modern file system, such as NTFS or APFS, the system gets slowed down when a directory contains a thousand or millions of files. Lookup, traversal, and metadata operations become slower, and tools like ls, rm, find take longer.
That’s why the hash_to_path function exists in our implementation, instead of putting all the files together in just one directory, which will hurt the performance, we instead break the hash into nested folders. For example, if we have the original hash like a1b2c3d4e5f6789, our hash_to_path function will then return the path as /objects/a1/b2/c3d4e5f6789.
Why is this better? There are a few reasons for this. The key feature of SHA-256 is that its output will be uniformly distributed over a 256-bit space, so any value in this space will have an equal chance of being generated, and the hash always appears as random.
Secondly, since the output of our ContentHash function is a fixed-length 64-character hash value; hence, each character will be represented by 4 bits, and 2 characters will be 8 bits. So the first two directory levels are derived from 2 bytes of the hash, which gives us a total of [math]256 * 256 = 65,536[/math] different directories. With 65,536 directories, each containing ~1000 files, performs significantly better than a single directory with 65M files. This is a good threshold for us to achieve a good performance when the files are evenly distributed, while it can keep looking up files fast, and keep the directory sizes small enough.
And then we write the other functions for adding and retrieving data from the PersistentStorage:
impl PersistentStore {
...
pub async fn put(&self, data: Vec<u8>) -> io::Result<ContentHash> {
let hash = ContentHash::from_bytes(&data);
let file_path = self.hash_to_path(&hash);
// check if file already exists (deduplication)
if file_path.exists() {
return Ok(hash);
}
// create parent directories
if let Some(parent) = file_path.parent() {
async_fs::create_dir_all(parent).await?;
}
// write data atomically using temporary file
let temp_path = file_path.with_extension("tmp");
async_fs::write(&temp_path, &data).await?;
async_fs::rename(&temp_path, &file_path).await?;
Ok(hash)
}
pub async fn get(&self, hash: &ContentHash) -> io::Result<Option<Vec<u8>>> {
let file_path = self.hash_to_path(hash);
match async_fs::read(file_path).await {
Ok(data) => {
// verify content integrity
let computed_hash = ContentHash::from_bytes(&data);
if computed_hash == *hash {
Ok(Some(data))
} else {
// corruption detected
Err(io::Error::new(io::ErrorKind::InvalidData, "corrupted data"))
}
}
Err(e) if e.kind() == io::ErrorKind::NotFound => Ok(None),
Err(e) => Err(e),
}
}
pub async fn contains(&self, hash: &ContentHash) -> bool {
self.hash_to_path(hash).exists()
}
}If we’re storing content-addressed data based on its hash. If two of the things below happen during the write, then we’ll be in trouble:
- Power loss, crash during write –> partial file
- Concurrent writes (e.g, two processes writing the same hash) –> race condition
Then, later reader sees half-written or corrupted data when the file is not written fully. That’s why in our put implementation, instead of getting the hash and writing to this file immediately, we create a temporary file, write to this temporary file, and then rename this temporary file to the original destination.
Writing to a temporary file and then renaming requires 2 different operations. But here in this case, only the latter operation needs to be atomic, because even if we fail in the former step, then the destination is still left untouched. Since Rust’s fs::rename(temp, final) API is atomic on a POSIX-compliant file system, which means once the rename function returns, either:
- The file didn’t exist
- Or it does, in its complete form
This technique is called “write-then-commit protocol”, a standard technique in system programming to achieve atomicity effectively over a non-atomic system.
The storage system that we’ve been building hashes the entire file content. This raises some questions: are large files also repeatedly hashed, and do small changes require re-storing the whole file? The answer to both of the questions is yes, it’s clearer if we take a look at an example:
impl PersistentStore {
...
pub async fn put(&self, data: Vec<u8>) -> io::Result<ContentHash> {
// problem: entire file must be in memory at once
let hash = ContentHash::from_bytes(&data); // hash entire file
if file_path.exists() {
return Ok(hash);
}
async_fs::write(file_path, &data).await?; // write entire file at once
Ok(hash)
}
}We read and write the entire file at once. Here is the usage that will break:
let video_file = tokio::fs::read("movie.mp4").await?; // 8GB file!
let hash = store.put(video_file).await?; // needs 8GB+ RAM!Indeed, this seems to be a problem when users start submitting large files, and multiple concurrent uploads on this occasion would probably break the system. Not only because of storage cost, but also the time for the hash function to finish would be slower and slower as the file size gets bigger. And if there is a file is uploading to our CAS system and suddenly gets disconnected, then nothing is then saved in our server.
Chunk-based Storage
Now it’s pretty natural for us to explore a better solution where we can get rid of or mitigate these problems. The answer for us at this point is “chunking“. Instead of treating files as atomic units, now we treat them as a collection of smaller, independently-addressable chunks.
First, we define a struct where we store a chunked file (a file that contains multiple smaller parts):
struct ChunkedFile {
total_size: u64,
chunks: Vec<ContentHash>,
}
pub struct ChunkedStore {
root: PathBuf,
}Next, we’re going to define the most important function in this phase, the store_file function, what it takes is a vector of bytes as input. If the file size is smaller or equal to the configured chunk size, we store it as a single chunk. Otherwise, we split the file into multiple fixed-size chunks before storing them:
pub async fn store_file(&self, data: Vec<u8>) -> io::Result<ContentHash> {
if data.len() <= CHUNK_SIZE {
// small file: store directly
return self.store_chunk(data).await;
};
// large file: split into chunks
let mut chunk_hashes = Vec::new();
for chunk_data in data.chunks(CHUNK_SIZE) {
let chunk_hash = self.store_chunk(chunk_data.to_vec()).await?;
chunk_hashes.push(chunk_hash);
};
// create metadata pointing to all chunks
let chunked_file = ChunkedFile {
chunks: chunk_hashes,
total_size: data.len() as u64
};
// store metadata
let metadata = bincode::serialize(&chunked_file).unwrap();
self.store_chunk(metadata).await
}
async fn store_chunk(&self, data: Vec<u8>) -> io::Result<ContentHash> {
let hash = ContentHash::from_bytes(&data);
let file_path = self.chunk_path(&hash);
if file_path.exists() {
return Ok(hash);
}
if let Some(parent) = file_path.parent() {
async_fs::create_dir_all(parent).await?;
}
async_fs::write(file_path, data).await?;
Ok(hash)
}
fn chunk_path(&self, hash: &ContentHash) -> PathBuf {
let hash_str = hash.as_str();
let mut path = self.root.clone();
path.push("chunks");
path.push(&hash_str[0..2]);
path.push(&hash_str[2..]);
path
}Here, one interesting detail is that we need to calculate the hashes for all the chunks before we can write the metadata. This metadata contains the hashes of all the chunks in the file and acts like a recipe to assemble them. This metadata is then hashed and saved at the end; later, we can use the hash of the metadata to reference all chunks again.
Let’s assume we have a large file that will need to be broken into 4 different chunks in our store_file function, for example, the hashes of those chunks could look like:
/storage/chunks/ab/c123... <- Just 64KB of raw data (bytes 0-65535)
/storage/chunks/de/f456... <- Just 64KB of raw data (bytes 65536-131071)
/storage/chunks/78/9xyz... <- Just 64KB of raw data (bytes 131072-196607)
/storage/chunks/11/1aaa... <- Just 8KB of raw data (bytes 196608-204799) After the last chunk is saved (in this case, the chunk ends with the hash 1aaa), then the metadata is
{
chunks: ["abc123", "def456", "789xyz", "111aaa"],
total_size: 200000
}This metadata is serialized and then stored in the location ending with the hash:
/storage/chunks/ma/in999... <- ChunkedFile metadata:Later in the future, if we want to get the file content again, we will use the hash of the metadata, deserialize it, and look into the chunk arrays to find out all the hashes and then retrieve the chunks as normal.

Also, the chunks are automatically deduplicated. If there are 2 different files and there is some common chunk between them, then the common chunk is stored only ONCE but can be used in BOTH of the files:
// File A: [chunk1, chunk2, chunk3]
let file_a = vec![/* some data */];
let hash_a = store.store_file(file_a).await?;
// File B: [chunk1, chunk4, chunk3] // Shares chunk1 and chunk3 with File A!
let file_b = vec![/* different data that happens to share some chunks */];
let hash_b = store.store_file(file_b).await?;
// Chunks (no file metadata):
// chunk1: just raw data
// chunk2: just raw data
// chunk3: just raw data
// chunk4: just raw data
// File metadata:
// file_a_metadata: { chunks: [chunk1, chunk2, chunk3], size: X }
// file_b_metadata: { chunks: [chunk1, chunk4, chunk3], size: Y }
// Note: chunk1 and chunk3 are stored only ONCE but used by TWO files!Conclusion
Content-addressable storage represents a fundamental shift from location-based to content-based addressing. We don’t say one is better than the other, but to pick one, it pretty much depends on the task we have. With CAS, it enables automatic deduplication since the identical content is stored only once, and it’s also used to check the data integrity of files since any change will generate different hashes. CAS isn’t just an academic concept; it’s the backbone of the systems that you use daily. Git uses SHA-256 hashes to address commits and objects, Docker images are stored using content-addressable layers, and modern build tools like Vite leverage CAS for efficient browser caching, and many other examples.